
A modest proposal. The idea is probably not new, but I find it very sensible indeed. Surely some basic knowledge about candidates can be expected from someone who wants to participate in deciding the political fate of a society!
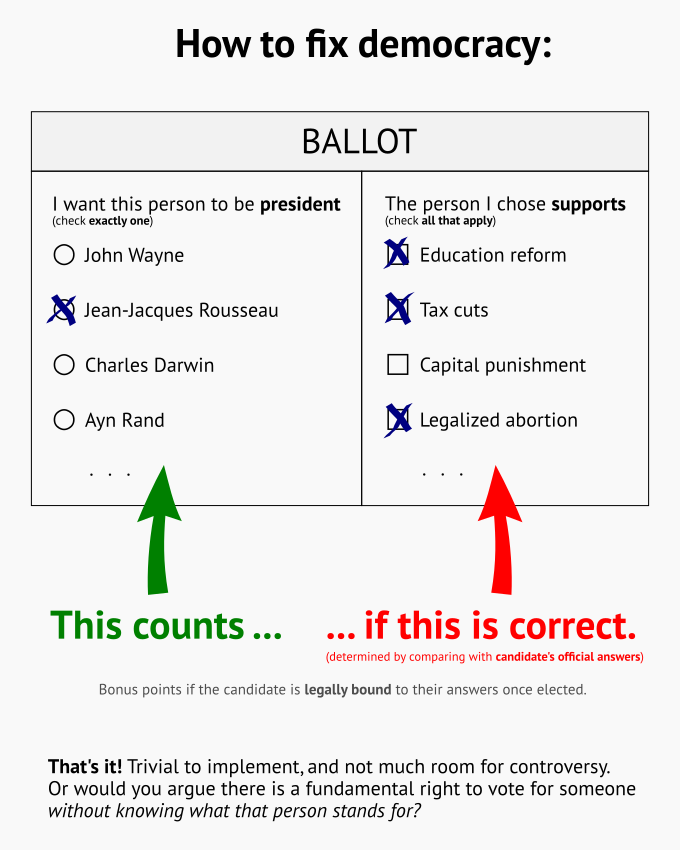
Yes, this may prevent some people from being able to cast a valid vote. No, this is not an unacceptable exclusion, any more than excluding toddlers from voting is. Seriously, if you have no idea what you are voting for, what are you doing with a ballot in your hand?
Cover image: "The Mascot", New Orleans (Wikimedia Commons, Public domain)
{kind=link}