
Krill are filter feeders. True to its namesake, krill filters feeds. It is not picky about its diet, and will happily consume RSS, Atom, CDF and even Twitter feeds (no credentials required!). It aggregates feed items from all sources you specify, filters out those that interest you, and displays them as a live stream of clean, legible command line output.
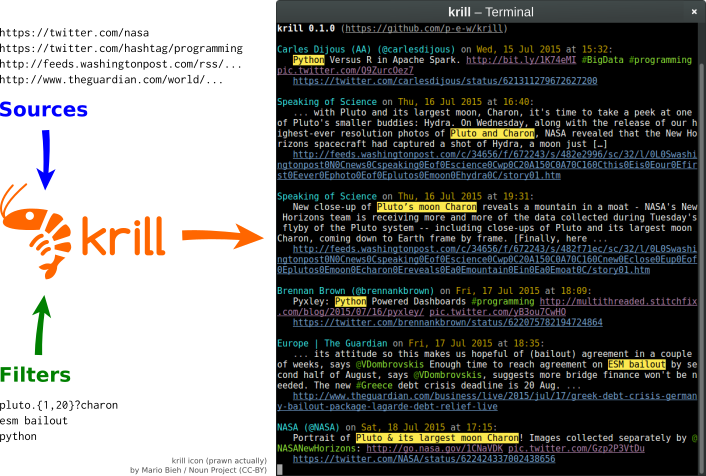
krill is beautifully minimal. krill is extremely easy to set up and use, and runs anywhere Python runs. krill is a refreshingly different way of consuming news and updates from anywhere on the web. krill is the hacker's way of keeping up with the world.
Installation
krill requires Python 2.7+/3.2+. If you have the pip package manager, all you need to do is run
pip install krill
either as a superuser or from a virtualenv environment.
Usage
Command line
krill [-h] [-s URL [URL ...]] [-S FILE] [-f REGEX [REGEX ...]]
[-F FILE] [-u SECONDS]
-s URL [URL ...], --sources URL [URL ...]
URLs to pull data from
-S FILE, --sources-file FILE
file from which to load source URLs (OPML format
assumed if filename ends with ".opml")
-f REGEX [REGEX ...], --filters REGEX [REGEX ...]
patterns used to select feed items to print
-F FILE, --filters-file FILE
file from which to load filter patterns
-u SECONDS, --update-interval SECONDS
time between successive feed updates (default: 300
seconds, 0 for single pull only)
Example
krill -s "https://twitter.com/nasa" -f "new ?horizons"
will follow NASA's Twitter stream, printing only tweets that mention the New Horizons probe.
krill automatically determines whether to treat a web document as a Twitter or an XML feed. If multiple sources and/or filters are loaded from a file with the -S and -F tags, each must be on a separate line (except if the sources file uses the OPML format, in which case all xmlUrl attributes are loaded). Empty lines and lines starting with # (comments) are ignored.
Any URL format accepted by the Requests library is supported. In particular, feeds requiring (basic) HTTP authentication can be accessed by supplying credentials in the URL string with https://user:password@example.com/feed.
Inline and file specifications may be combined freely. If more than one filter is given, items matching any of the filters are printed. If no filter is given, all items are printed.
Cover image: Uwe Kils (Wikimedia Commons, CC-BY-SA)
{kind=link}